El material genético de los organismos contiene información vital para su funcionamiento, razón por la cual es necesario garantizar su estabilidad y su inmutabilidad. Sin embargo, y a pesar de que los seres vivos poseen mecanismos para asegurarse la fidelidad de los procesos de copia de la información, de vez en cuando se producen cambios en la secuencia de nucleótidos que constituyen el genoma de los organismos. Cualquier cambio de este tipo recibe el nombre de mutación.
Las mutaciones se deben siempre a la acción de agentes, físicos o químicos, que interaccionan con el ADN celular, alterándolo. Los agentes físicos son algún tipo de energía que puede ser "absorbida" por el material genético, provocando modificaciones en él. Entre este tipo de fenómenos se encuentran las fuentes de radiación como rayos gamma, X o ultravioleta, que pueden interferir con esta molécula; las radiaciones más energéticas pueden llegar a romper físicamente los cromosomas, mientras que las de menor contenido energético, como los rayos ultravioleta, pueden ser absorbidos por algunas bases del ADN que, como resultado de ese proceso, ven cambiar su estructura química, o reaccionan con las bases vecinas.
Los agentes mutágenos también pueden ser sustancias químicas. En este caso, puede tratarse de compuestos capaces de reaccionar con alguno de los componentes del ADN (por ejemplo los agentes intercalantes, que se introducen dentro de la doble hélice y pueden formar enlaces covalentes con las bases nitrogenadas) o, incluso, pueden ser introducidos dentro de la molécula de ADN en lugar de alguna de las bases correctas (análogos de bases).
Clasificación de las mutaciones
Las mutaciones pueden clasificarse en función de diferentes criterios, todos ellos de cierta importancia a la hora de entender los efectos que producen:
- Según las células que resultan afectadas
- Mutaciones somáticas: no se transmiten a la descendencia, pero pueden alterar de un modo considerable su funcionamiento y el del organismo en general. El cáncer puede ser el resultado de mutaciones somáticas.
- Mutaciones germinales: se producen en células de la línea germinal, que darán origen a gametos, por lo que pueden transmitirse a la descendencia del organismo.
- Según la causa que las produce:
- Naturales o espontáneas: son producidas por agentes presentes en el entorno de modo natural.
- Inducidas: producidas por agentes mutágenos.
- Según los efectos que producen sobre el organismo:
- Neutras, si no afectan a la capacidad de supervivencia. Ocurren, por ejemplo, cuando cambia un codón por otro sinónimo.
- Beneficiosas, si incrementan las posibilidades de supervivencia del organismo.
- Perjudiciales, que a su vez pueden ser:
- Letales, si producen la muerte de al menos el 90% de sus portadores.
- Subletales, si provocan la muerte de menos del 10% de los portadores
- Patológicas, si dan lugar a alguna enfermedad.
- Según el tipo de determinación genética que suponen:
- Dominantes
- Recesivas
- Condicionales: solo se manifiestan cuando se dan determinadas circunstancias ambientales.
- Según la alteración genética producida:
- Génicas: afectan a la secuencia de un solo gen.
- Cromosomicas: alteran la estructura de los cromosomas.
- Genómicas: cambian el número de cromosomas.
Las posibles consecuencias de las mutaciones para una célula o un organismo son muy variables, y pueden suponer la muerte del individuo que las porta (mutaciones deletéreas) o, en casos menos graves, cambios morfológicos o pérdida de función de uno o varios genes. Un caso particular de pérdida de función de un gen lo constituyen las mutaciones bioquímicas o nutritivas, que suponen la imposibilidad de que la célula pueda utilizar o metabolizar algún compuesto químico. A escala de individuo completo, algunas mutaciones de este tipo son la intolerancia a la lactosa, la enfermedad celiaca o la fenilcetonuria (PKU). Muchas de estas mutaciones bioquímicas son, típicamente, mutaciones en las que solo está afectado un gen.
Mucho menos frecuentes, pero de gran interés desde el punto de vista evolutivo, son las mutaciones en las que se produce la ganancia de función por parte de algún gen. En estos casos, si existen varias copias del mismo gen (lo que es bastante frecuente en los eucariotas) el organismo mantiene la función original, al tiempo que se puede beneficiar de la nueva función adquirida. Este hecho explica la importancia del "ADN basura", que en realidad representa para los organismos una importante reserva de material genético a partir de la cual desarrollar, mediante mutaciones, nuevas capacidades que pueden llegar a resultarles de utilidad.

Las mutaciones génicas o puntuales son aquellas que afectan solo a un gen. En general, se deben a la ocurrencia de errores durante la replicación del ADN que escapan a la reparación por parte de alguno de los sistemas de reparación con los que cuenta la célula. Se pueden distinguir varios tipos de mutaciones génicas:
- Sustituciones de una base por otra. Casi siempre afectan a un único triplete, y por lo tanto suponen, como mucho, el cambio de un aminoácido por otro en la proteína resultante. Excepciones a esto se produce si el triplete que resulta de la mutación da lugar a un codón stop, en cuyo caso el resultado final es una proteína "truncada", más corta que la original y, por lo tanto, muy probablemente inútil, o si se ven afectados los puntos de splicing, es decir, las zonas que determinan el inicio y el final de los exones. Además, si la mutación se produce en la última base de un codógeno, es muy probable que sea una mutación "silenciosa", porque frecuentemente dará lugar a un codón sinónimo del original. Existen dos posibles tipos de sustitución:
- Transiciones, que suponen el cambio de una base por otra del mismo grupo (purina por purina o pirimidina por pirimidina)
- Transversiones, que suponen el cambio de una purina por una pirimidina o viceversa.

- Mutaciones que afectan al marco de lectura: se trata de cambios en el número de nucleótidos de la cadena. Como la lectura en el ribosoma se produce de forma "modular", es decir, el ribosoma lee los codones tomando la cadena de ARN de tres en tres nucleótidos, este tipo de mutaciones supone el cambio de la secuencia de la proteína a partir del punto en el que se ha producido la mutación. El resultado es una proteína totalmente diferente a la original, que puede ser más larga o más corta en función de dónde aparezca el nuevo codón de stop.
- Adición o inserción: consisten en la introducción de una base de más en la cadena de ADN.
- Supresión o deleción de una base.


El término mutaciones cromosómicas hace referencia a aquellos cambios en el material genético que modifican la estructura de uno o varios cromosomas. Como estas estructuras son observables mediante microscopía óptica, y como pueden "mapearse" mediante técnicas de tinción diferencial que dan lugar a la aparición de bandas de diferente color, las mutaciones cromosómicas resultan fácilmente visibles, lo que ha hecho de ellas un objeto de estudio desde hace mucho tiempo. Básicamente se distinguen dos grandes grupos de modificaciones de este tipo: las que suponen un cambio en el número de genes (por adición o eliminación) y las que "solo" producen un cambio en la posición de los genes.
Deleciones: consisten en la pérdida de un fragmento cromosómico, lo que puede ocurrir tanto en uno de los extremos del cromosoma como en su parte intermedia. Cuando ocurren en ambos cromosomas homólogos suelen provocar la muerte del individuo que las porta, por la falta de genes que supone. En heterocigosis su efecto depende del tamaño del fragmento. En humanos, la deleción apreciable más significativa es la pérdida de un fragmento del brazo corto del cromosoma 5, que da lugar a una enfermedad llamada "Grito del gato", que produce la muerte de los niños al poco de su nacimiento.


- Duplicaciones: consisten en la aparición repetida de un fragmento de cromosoma como consecuencia de un error durante la replicación. En general, las mutaciones no producen consecuencias perjudiciales. Más bien al contrario, proporcionan material genético nuevo que puede facilitar la evolución, ya que los genes originales siguen existiendo. Muchas familias de genes que dan lugar a proteínas relacionadas tienen este origen.

- Inversiones: son reorganizaciones de fragmentos de un cromosoma que cambian su orientación respecto al resto del cromosoma, para lo cual ha tenido que producirse la rotura completa de ambas cadenas de ADN, un giro de 180º del fragmento, y su unión en la dirección incorrecta. Pueden afectar al centrómero (inversión pericéntrica) o dejarlo fuera (inversión paracéntrica). Aunque en principio podría parecer que las inversiones no afectan al contenido de la información genética del organismo, en realidad sí que tienen influencia, porque afectan a la meiosis: los fragmentos invertidos no se aparean con su cromosoma homólogo, y los genes incluidos en ellos no se recombinan.

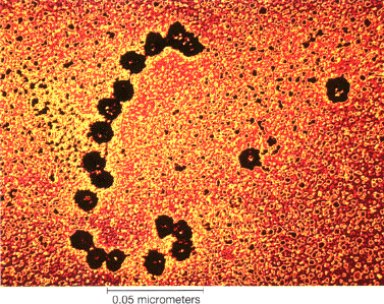
- Translocaciones: consisten en el desplazamiento de un fragmento de cromosoma a otro lugar del genoma. Puede tratarse de translocaciones no recíprocas, si solo se produce el movimiento de un fragmento, o de translocaciones recíprocas, si se produce el intercambio entre fragmentos de dos cromosomas no homólogos. En la especie humana, uno de los casos más frecuentes es la translocación de casi todo el cromosoma 21 al brazo corto del cromosoma 14 (imagen de la derecha), que da lugar a un individuo con 45 cromosomas pero que puede ser fértil. En este caso se produce el "Síndrome de Down familiar", única circunstancia en la que esta enfermedad puede heredarse. Las translocaciones pueden tener gran importancia evolutiva, ya que pueden dar lugar a poblaciones de la misma especie con un número diferente de cromosomas, lo que se traduce en que ambos grupos quedan aislados genéticamente entre sí lo que, finalmente, provocará que formen especies distintas.

Mutaciones genómicas
Se utiliza este concepto para definir los cambios en el material genético de un organismo que suponen un cambio en su número de cromosomas. Siempre producen consecuencias graves en el individuo, especialmente cuando provocan una pérdida de material genético. Las mutaciones de este tipo que tienen mayor posibilidad de dar lugar a individuos viables si los cromosomas afectados son muy pequeños o los que determinan el sexo del individuo.
Se distinguen dos tipos de mutaciones genómicas: las que afectan a juegos de cromosomas completos, que reciben el nombre de euploidías (porque cambian la ploidía, el número de cromosomas característico de la especie) y las que provocan la variación en el número de unos pocos cromosomas, que reciben el nombre de aneuploidías:
- Euploidías: son muy poco frecuentes en animales, pero relativamente habituales en vegetales, en los que suelen dar lugar a nuevas variedades.
- Monoploidía o haploidia: consiste en la pérdida de un juego completo de cromosomas por parte del individuo, con lo cual todas sus células son haploides, como los gametos. Existen algunos organismos que son haploides al menos en algunas fases de su vida, pero aparte de esos casos la haploidía es rara. Si los individuos de este tipo sobreviven, pequeño tamaño y poco vigorosos. En todo caso sus gametos son inviables. Es posible beneficiarse de la haploidia inducida, si se puede lograr duplicar los cromosomas de un individuo de este tipo, porque se obtiene un organismo totalmente homocigoto, lo que es prácticamente imposible por otros mecanismos.
- Poliploidía: se trata del proceso por el cual un organismo aumenta su número de juegos cromosómicos completos. Cuando el organismo sobrevive, lo que ocurre mucho más frecuentemente en plantas que en animales, tiende a ser más grande y más vigoroso que el diploide normal. En vegetales, la poliploidía puede producirse por duplicación del genoma de un único individuo o por hibridación con otra especie (aloploidía). La poliploidía ha sido utilizada habitualmente como mecanismo de mejora genética en vegetales.
- Aneuploidías: falta o sobra algún cromosoma respecto de la dotación correcta, pero no el juego completo.
- Nulisomía: faltan los dos cromosomas del mismo par. En general tiene efectos letales, porque el individuo carece por completo de esos genes.
- Monosomía: Falta una de las copias del cromosoma. En humanos, el único ejemplo de monosomía total (falta de todo el cromosoma) es el síndrome de Turner, consistente en que los individuos que lo presentan poseen un único cromosoma sexual (X0).
- Trisomía: un cromosoma posee tres copias en lugar de dos. En general, los individuos que la portan son inviables o presentan graves trastornos de todo tipo. En humanos la más conocida es la trisomía del cromosoma 21, que da lugar al síndrome de Down, aunque también pueden producirse trisomías de los cromosomas sexuales (síndrome de Klinefelter, XXY, síndrome de triple X, síndrome XYY, muy relacionado con comportamientos muy violentos) o de otros autosomas, si bien mayoritariamente son inviables.
- Tetrasomías y pentasomías: aunque son extremadamente raras, se conocen casos de individuos con cuatro o cinco cromosomas sexuales, en diversas combinaciones.
Todos los seres vivos son el resultado de un proceso de evolución biológica que se ha producido como consecuencia de un ciclo de variación genética - presión selectiva - selección. Aunque existen diferentes mecanismos para que una variación de las características genéticas se extienda por una población, solo hay un mecanismo molecular posible para originar esa variación: la mutación, en cualquiera de sus formas.
No todos los tipos de mutaciones son igualmente productivos en términos de posibilidades evolutivas. Los más interesantes desde ese punto de vista son los que permiten la aparición de nuevas características sin pérdida de las originales, porque proporcionan al organismo más posibilidades biológicas de las que tenía. En este sentido, cobran una importancia particular los mecanismos de duplicación (mutación cromosómica) y poliploidía, que proporcionan material genético nuevo, que se añade al que ya existía. Tras esos primeros procesos, las mutaciones puntuales, capaces de modificar la funcionalidad de las proteínas, explican la aparición de alelos nuevos, que pueden tener (o no) características ventajosas.