El último paso en la expresión de la información genética es la elaboración de proteínas, las moléculas que realizan la práctica totalidad de las funciones celulares. La célula tiene miles de proteínas distintas, cada una de las cuales es capaz de llevar a cabo un proceso biológico (catálisis de una reacción química, reconocimiento de señales, transporte de sustancias...) gracias a que su estructura tridimensional se adapta a dicho proceso y, a su vez, esa adaptación entre estructura y función es posible porque la estructura de cada proteína está perfectamente establecida, de modo que cuando se elabora una nueva molécula de esa sustancia existe la seguridad de que va a ser idéntica a todas las demás moléculas de ese tipo que existen en la célula.
Para que eso sea posible es necesario contar con dos elementos que garanticen el proceso: un sistema que almacene la información y la transmita de forma segura y fiable y otro que permita utilizar esa información, "leerla", para elaborar la proteína concreta. El primer sistema es la replicación del ADN. El segundo incluye, a su vez, dos pasos: la transcripción, que transfiere la información al ARN, y la traducción, que es el proceso concreto mediante el cual la célula utiliza la información contenida en el ARN mensajero para producir una proteína determinada.
El proceso de traducción, que "concluye" la expresión genética, resulta de importancia vital para el funcionamiento de los organismos. Cada célula necesita tener, en cada momento, un subconjunto concreto de las proteínas que es teóricamente capaz de producir, en una cantidad concreta, ni más ni menos, y cada una de esas proteínas debe poseer la secuencia precisa de aminoácidos para ser funcional. Cualquier error en ese proceso supone consecuencias negativas para la célula; en el rango más bajo, que la proteína errónea no sirva para nada, con lo que la célula habrá desperdiciado recursos y energía en la elaboración de una molécula inútil. En el peor de los casos, el mal funcionamiento de una o unas pocas proteínas puede hacer que la célula en su conjunto trabaje de forma errónea, lo que puede llevarle al suicidio celular (la apoptosis es un proceso programado mediante el cual una célula que funciona de modo incorrecto se autodestruye) o a su transformación en una célula maligna, que puede ser el inicio de un tumor.
Traducción e información
La síntesis de una proteína determinada necesita, como ya se ha comentado muchas veces, información. A diferencia de lo que ocurre con los homopolímeros, cada monómero que se incorpora a la cadena puede ser diferente. El proceso también es diferente a lo que ocurre en la formación de heteropolímeros "regulares", como los heteropolisacáridos, en los que existe una pauta que se repite regularmente. En su lugar, en la síntesis de proteínas es necesario que se incorpore en cada posición un aminoácido concreto, sin que exista ningún patrón regular que determine cuál debe ser para conseguir que la proteína alcance su estructura primaria correcta, de la que dependerán el resto de los niveles estructurales y, finalmente, su función. Por ello, hace falta un "modelo" cuya información seguir. Este modelo es, precisamente, el ácido ribonucleico mensajero.
La información que contiene el ARN mensajero está codificada en un lenguaje de cuatro símbolos, las cuatro bases que varían en él, mientras que cada proteína puede necesitar hasta veinte tipos distintos de aminoácidos para formarse. Los símbolos del ARN se agrupan de tres en tres formando "palabras", con lo que existen 64 combinaciones distintas, cada una de las cuales puede dar lugar a un único aminoácido. La relación que existe entre las diferentes "palabras" de ARN, más propiamente llamadas tripletes de bases o codones, y los aminoácidos a cuya incorporación en la proteína corresponden constituye el código genético.
Resumiendo: la célula utiliza dos lenguajes diferentes para gestionar su información: uno, el de los ácidos nucleicos, posee cuatro símbolos distintos combinados para formar "palabras" de tres unidades cada una, por lo que cuenta con un total de 64 elementos diferentes. El nombre que recibe cada uno de esos elementos es distinto en función de en qué molécula se encuentren: se denominan codógenos cuando hablamos del ADN, codones si nos referimos al ARN mensajero y sus moléculas complementarias en el ARN transferente reciben el nombre de anticodones. El otro lenguaje es el de las proteínas, que utiliza veinte "palabras" unitarias, los aminoácidos. Existe, por último, una relación, una "tabla de equivalencias" entre las palabras de los dos idiomas, que recibe el nombre de código genético.
La diferencia en el número de elementos entre los dos lenguajes no es demasiado grave; por una parte, tres de los codones no tienen "traducción" en el lenguaje de las proteínas, y reciben el nombre de codones "sin sentido", aunque en realidad juegan un papel fundamental: el de indicar que se ha alcanzado el final del mensaje, por lo que reciben también el nombre, mucho más apropiado, de "codones stop". Por otra parte, puede darse el caso de que varios codones "signifiquen" lo mismo en el lenguaje de las proteínas, por lo que se habla de "codones sinónimos". Hay que destacar que esto no "degrada" el mensaje, porque la información necesaria para llevar a cabo los procesos celulares es la que está codificada en las proteínas, y la existencia de codones sinónimos no supone ninguna ambigüedad. La existencia de codones sinónimos, es decir, de combinaciones diferentes de bases que dan lugar al mismo aminoácido, es una de las características del código genético. Para referirse a ella se suele decir que el código genético está degenerado.
El código tiene otras características fundamentales para comprender el funcionamiento de la expresión genética. Tales características son las siguientes:
- Es un código lineal, lo que significa que las "palabras" en lenguaje de ácidos nucleicos son leidas secuencialmente, y traducidas también secuencialmente al lenguaje de las proteínas. Esto establece una equivalencia "uno a uno": un codón es responsable de la inclusión de un aminoácido en la proteína en formación.
- Es continuo, lo que significa que no hay "espacios" entre palabra y palabra: todas las bases nitrogenadas de un fragmento de ARN mensajero se utilizan en la síntesis de proteínas, de modo que no queda ninguna entre la última de un codón y la primera del siguiente.
- Es universal (o casi): todos los seres vivos utilizan el mismo código genético. Esto es una muestra de la antigüedad y de la importancia del código. De su antigüedad, porque todos los seres vivos lo comparten, lo que significa que todos ellos proceden del mismo antepasado común que ya lo utilizaba. De su importancia, porque demuestra que las mutaciones que, a lo largo del proceso evolutivo, necesariamente ha tenido que sufrir, no han podido mantenerse en los organismos, debido a que sus efectos negativos lo impedían.
En realidad, el análisis de la degeneración del código, y de pequeñas modificaciones del mismo que se dan en bacterias, mitocondrias y cloroplastos, ha llevado a formular una hipótesis acerca de su posible evolución. Se supone que, en un pasado muy remoto, debieron existir organismos que necesitaban un menor número de aminoácidos para producir sus proteínas, por lo que el código genético podría haber sido más sencillo, concretamente de dos bases por aminoácido. Sin embargo, el incremento de la complejidad de los organismos debió forzarles a incorporar un mayor número de aminoácidos por proteína, razón por la cual el código debió pasar de tener dos bases por aminoácido a tener tres bases por aminoácidos. Esto explicaría el hecho de que prácticamente todos los codones sinónimos compartan las dos primeras bases (las que habrían servido para uno de los aminoácidos en la primera fase de la evolución) y difieran en la tercera.
El proceso de traducción
Como todos los procesos bioquímicos, la traducción necesita un aparataje molecular, es decir, cada uno de los pasos que ocurren durante el proceso global de síntesis de una proteína suceden gracias a la intervención física de un grupo de moléculas. En este caso, como cabe esperar de un proceso tan complejo, el aparato molecular que interviene también lo es, e incluye los precursores de la proteína que se va a sintetizar (aminoácidos, nucleótidos trifosfato para proporcionar energía), un grupo amplio de proteínas y diferentes tipos de ácidos ribonucleicos, algunos de ellos integrados en un complejo macromolecular de gran tamaño que es el que desarrolla la síntesis: el ribosoma.
En la síntesis de proteínas intervienen los tres tipos de ARN que se encuentran en la célula: el ARN mensajero es el que lleva la información genética a partir de la cual se copiará la proteína, el ARN ribosómico, unido a varias proteínas, constituye la "maquina" que lleva a cabo físicamente la síntesis, y el ARN transferente establece la relación entre la información del mensajero y el aminoácido que corresponde a cada codón.
En la célula existen 61 tipos de ARNt, todos ellos con una estructura similar (aproximadamente en forma de "L") pero con secuencias de nucleótidos distintas. En particular, todos ellos se diferencian en uno de sus "lazos", zonas en las que no se da complementariedad de bases intramolecular. Ese lazo, llamado lazo anticodón, incluye tres nucleótidos que van a ser complementarios de los codones del ARN mensajero. En el extremo 3' del ARNt puede unirse un aminoácido, que será distinto según sea la secuencia del brazo anticodón.
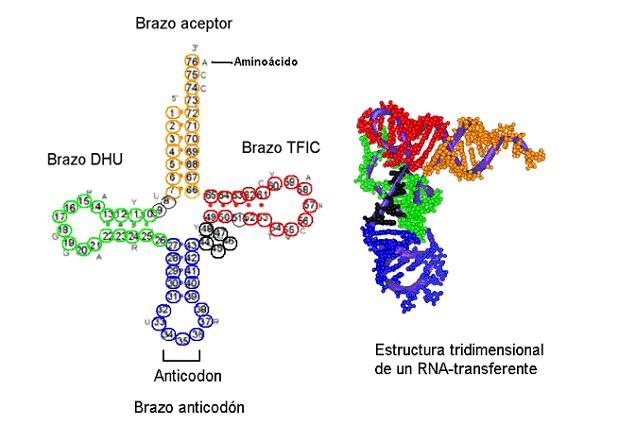
Para que los aminoácidos puedan incorporarse a la proteína deben estar unidos al ARN transferente que le corresponde. La unión se lleva a cabo por la acción de enzimas llamadas aminoacil-ARNt transferasas, que son específicas para el aminoácido y para el ARNt, y requiere energía que es proporcionada por el ATP.
El proceso de traducción ocurre en el ribosoma, un complejo nucleoproteico formado por ARN ribosómico y proteínas. Estructuralmente, consta de dos subunidades que están separadas cuando el ribosoma está inactivo. Para que se inicie la síntesis de la proteína el ARN mensajero debe unirse a la subunidad pequeña, y una vez formado este complejo ambos elementos se unen a la subunidad grande.
Cuando el ribosoma está ensamblado se forman en él tres "sitios", en los que se van a producir los diferentes procesos que permiten la formación de la proteína:
El proceso de traducción ocurre en el ribosoma, un complejo nucleoproteico formado por ARN ribosómico y proteínas. Estructuralmente, consta de dos subunidades que están separadas cuando el ribosoma está inactivo. Para que se inicie la síntesis de la proteína el ARN mensajero debe unirse a la subunidad pequeña, y una vez formado este complejo ambos elementos se unen a la subunidad grande.
Cuando el ribosoma está ensamblado se forman en él tres "sitios", en los que se van a producir los diferentes procesos que permiten la formación de la proteína:
- El Sitio P es el lugar por donde la proteína en formación permanece unida al ribosoma.
- El Sitio A es la parte del ribosoma por donde se incorpora el nuevo aminoácido que se va a unir a la proteína.
- El Sitio E es el lugar por donde el ARNt abandona el ribosoma una vez que ha liberado el aminoácido y que éste se ha unido a la cadena creciente.
A medida que la proteína va creciendo, el ribosoma avanza a lo largo de la molécula de ARN mensajero. Es muy frecuente que cada molécula de ARN mensajero sea leida sucesivamente por varios ribosomas, de modo que se sintetizan casi simultáneamente varias copias de la misma proteína.
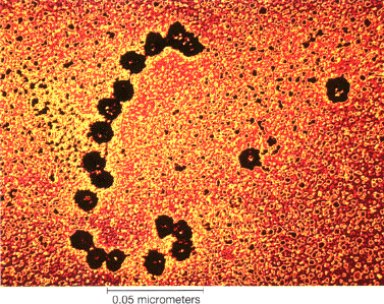
El conjunto formado por un ARN mensajero y varios ribosomas que lo leen simultáneamente se denomina polirribosoma, y puede observarse con frecuencia en micrografías electrónicas. Esta es una estrategia que permite la obtención de una gran cantidad de una proteína antes de que el ARN mensajero sea degradado, lo que ocurre con mucha rapidez.
Las fases de la traducción
- Iniciación: Incluye la unión entre el ARN mensajero y el ribosoma, la unión de las dos subunidades y la incorporación del primer aminoácido.
- Elongación: Consiste en la incorporación sucesiva de los aminoácidos.
- Terminación: Se produce cuando el ribosoma lee un codón de stop. En ese momento, la proteína formada abandona el ribosoma y sus subunidades se separan.
En procariotas en esta fase intervienen tres proteínas llamadas factores de iniciación (IF 1, 2 y 3) que deben unirse a los otros elementos para que el proceso tenga lugar. Antes de empezar la traducción las subunidades del ribosoma se encuentran separadas entre sí. El primer paso de la traducción es la unión de la subunidad pequeña (30S) del ribosoma con dos de los factores de iniciación, IF1 e IF3. Este grupo de moléculas se une al ARN mensajero en una secuencia específica, que se localiza antes (más cerca del extremo 5' de la molécula) del codón de iniciación.
En los organismos procariotas el primer aminoácido que se introduce en la cadena es siempre la metionina, que corresponde al codón AUG (codón de iniciación), aunque cuando la proteína está terminada este aminoácido se elimina. La metionina, unida a su ARNt correspondiente, debe unirse al otro factor de iniciación (IF2) y las tres moléculas se asocian al complejo formado por los otros factores de iniciación, el ARNm y la subunidad pequeña del ribosoma.
Finalmente, la subunidad grande se une a todas estas moléculas, dejando al ARNt+metionina en el sitio P del ribosoma recién formado, y forzando la salida de los factores de iniciación. La estructura formada, compuesta por el ribosoma, el ARN mensajero y el ARNt con la metionina en el sitio P recibe el nombre de complejo de iniciación.
El desarrollo de este proceso requiere energía, que es aportada por la hidrólisis de GTP.
Elongación
La elongación es un proceso que se repite tantas veces como aminoácidos tenga la proteína (menos el de iniciación). Globalmente consiste en añadir un aminoácido a la cadena que se está formando, y dejar el ARNt junto con la cadena creciente en el sitio P del ribosoma, para permitir la entrada del siguiente aminoácido.
El proceso se inicia con un ARNt unido químicamente a un aminoácido o a una cadena, y situado en el sitio P. El siguiente ARNt en incorporarse se acerca al sitio A, que está libre; si su brazo anticodón es complementario del codón situado frente al sitio A, y si lleva el aminoácido correspondiente en su extremo 3', el ARNt se queda fijado en el ribosoma. La cadena de aminoácidos del sitio P se libera de su ARNt y forma un enlace con el nuevo aminoácido, con lo que el ARNt "descargado" puede abandonar el ribosoma. Por último, el ribosoma en su conjunto avanza la distancia de un codón sobre el ARN mensajero, dejando en el sitio P al ARNt "cargado" con la cadena de proteína creciente.
La energía consumida en este proceso es aportada, de nuevo, por el GTP.
La elongación de la proteína ocurre desde el extremo N-terminal (primer aminoácido que se incorpora) hacia el C-terminal.
Terminación
El proceso de elongación se produce repetidamente hasta que el sitio A del ribosoma queda situado frente a un codón stop (UGA, UAG o UAA). La célula no posee ningún ARNt con un brazo anticodón complementario de estos codones, por lo que el sitio A queda vacío hasta que se une a él una proteína, el factor de liberación. El grupo carboxilo del último aminoácido reacciona con el agua, con lo que la proteína, ya completa, se separa del ARNt y abandona el ribosoma.
Cuando la proteína abandona el ribosoma, éste se descompone en sus partes constituyentes, separándose sus subunidades, que pueden volver a ser utilizadas. El ARN mensajero, por su parte, es degradado y sus nucleótidos son reciclados en la elaboración de otras moléculas.
Esta fase también obtiene la energía que necesita de la hidrólisis del GTP.El proceso se inicia con un ARNt unido químicamente a un aminoácido o a una cadena, y situado en el sitio P. El siguiente ARNt en incorporarse se acerca al sitio A, que está libre; si su brazo anticodón es complementario del codón situado frente al sitio A, y si lleva el aminoácido correspondiente en su extremo 3', el ARNt se queda fijado en el ribosoma. La cadena de aminoácidos del sitio P se libera de su ARNt y forma un enlace con el nuevo aminoácido, con lo que el ARNt "descargado" puede abandonar el ribosoma. Por último, el ribosoma en su conjunto avanza la distancia de un codón sobre el ARN mensajero, dejando en el sitio P al ARNt "cargado" con la cadena de proteína creciente.
La energía consumida en este proceso es aportada, de nuevo, por el GTP.
La elongación de la proteína ocurre desde el extremo N-terminal (primer aminoácido que se incorpora) hacia el C-terminal.
Terminación
El proceso de elongación se produce repetidamente hasta que el sitio A del ribosoma queda situado frente a un codón stop (UGA, UAG o UAA). La célula no posee ningún ARNt con un brazo anticodón complementario de estos codones, por lo que el sitio A queda vacío hasta que se une a él una proteína, el factor de liberación. El grupo carboxilo del último aminoácido reacciona con el agua, con lo que la proteína, ya completa, se separa del ARNt y abandona el ribosoma.
Cuando la proteína abandona el ribosoma, éste se descompone en sus partes constituyentes, separándose sus subunidades, que pueden volver a ser utilizadas. El ARN mensajero, por su parte, es degradado y sus nucleótidos son reciclados en la elaboración de otras moléculas.
Diferencias en la traducción entre procariotas y eucariotas
El proceso de traducción es relativamente diferente en los eucariotas, empezando por las características de las propias moléculas de ARN: en eucariotas, cada molécula de ARN mensajero codifica para una sola proteínas (son monocistrónicos), mientras que en procariotas es frecuente que una única molécula de ARNm lleve información correspondiente a varias proteínas (genes policistrónicos). También es diferente la estabilidad de la molécula, mayor en los eucariotas que en los procariotas.
El primer aminoácido que se incorpora a la proteína también cambia entre procariotas y eucariotas: en los procariotas se incorpora inicialmente una molécula de metionina, pero está modificada químicamente (es, en realidad, formil-metionina), mientras que en eucariotas se incorpora como primer aminoácido una metionina no modificada.
Por último, también son distintos los elementos que constituyen el complejo de iniciación, y hasta el orden en el que se forma dicho complejo.
Excelente información!
ResponderEliminar